参考链接:
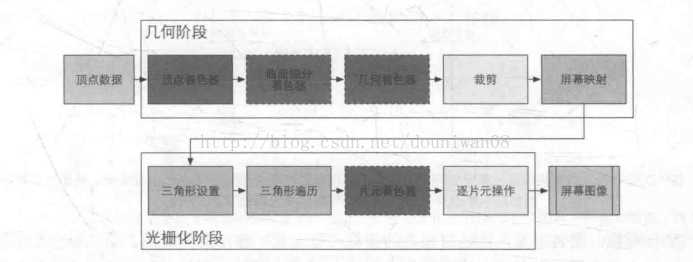
OpenGL的固定功能管线
转自:OpenGL: 渲染管线理论
我的理解就是顶点->图元->光栅->片元->帧缓冲
阶段1. 指定几何对象
如:点 线 三角形.等一些几何图元..OpenGL绘制几何图元的方法有以下三种:
- <1> 一次一个顶点.即使用glBegin() glVertex() glEnd() 指定几何对象.
- <2> 使用顶点数组.如glDrawArrays.glDrawElements.等.一次性的绘制大量图元.
上面这两种模式则是立即模式.即指定完图元之后会被立即渲染.即将所有数据发往渲染管线后立即被渲染.
- <3>显示列表模式.它存储于OpenGL服务端 (接收OpenGL命令的一端),操作函数有 glNewList、 glEndList、 glCallList .
阶段2 顶点处理操作:
不管以上的几何对象是如何指定的,所有的几何数据都将会经过这个阶段,这个阶段负责的则是逐个顶点的操作.
在这个阶段能做的工作则是:
- <1>顶点变换:根据模型视图和投影矩阵变换
- <2>光照计算和法线变换(法线矩阵 是模型矩阵的左上角3*3的逆矩阵)和法线规格化
- <3>纹理坐标变换.(纹理矩阵)
- <4>材质状态:纹理坐标生成
而最重要的则是变换以及光照. 每个顶点在这个阶段分别是单独处理的.
这个阶段所接收到的数据则是每个顶点的属性特征..输出则是变换后的顶点数据.
阶段3 图元组装
在顶点处理之后,顶点的全部属性都已经被确定。在这个阶段顶点将会根据应用程序送往的图元规则如GL_POINTS 、GL_TRIANGLES 等将会被组装成图元。
阶段4 图元处理(裁剪 消隐)
- <1>这个步骤第一个所做的应当是裁剪操作,会将图元与用户定义的裁剪平面,即glClipPlane 和模型投影矩阵所建立的视景比较. 这将会裁剪且丢弃位于视景和裁剪平面外部的图元.不在予以处理.
- <2> 其次.若是采用透视投影 那么.将会对每个顶点的x,y z坐标分别除以w.
- <3>紧接着,则是由视口变换将顶点坐标变换至窗口坐标.
- <4> 执行消隐操作
阶段5 栅格化操作
- <1>由图元处理传递过来的图元数据.在此将会被分解成更小的单元并对应帧缓冲区的各个像素.这些单元被称之为片元. 一个片元可能包含窗口左边、深度、颜色、纹理坐标等属性.
- <2> 片元的属性则是图元上顶点数据等经过插值而确定的..这里生成的片元将会包含主颜色和次颜色. glShadeMode() 函数的作用将会这里体现.即使用插值(平滑着色) 或者使用最后一个顶点颜色(平面着色)
- <3> 点宽 线宽.多边形模式,正面背面等一些特征也将是这阶段发生作用.
- <4> 反走样也是这个阶段起作用.
阶段6 片元处理
- <1>上纹理:通过纹理坐标取得纹理内存中相对应的颜色。
- <2> 雾化:通过片元距离当前视点位置修改颜色.
- <3> 颜色汇总..这个与混合完全不同概念.将纹理,主定义的颜色,雾化的颜色,次颜色光照阶段计算的颜色 汇总一起.
阶段7 逐个片元的操作
- <1> 所有的一些测试 像素所有权 剪切(glScissor) Alpha测试(glAlphaFunc) 模版测试(glStencilFunc) 深度测试 (glDephtFunc) 混合(glBlendFunc)
这些操作将会最后影响其在帧缓冲区的颜色值.
阶段8 帧缓冲操作
- <1>这个阶段执行帧缓冲的写入等操作等..最后产生了显示出来的像素.
glColorMask、glStrncilMask、glDepthMask、glClearDepht、glClearStencil、glClearColor 等.将在这个阶段影响写入的值.
以上只是讨论OpenGL 图元绘制的基本过程 那么基于像素图像绘制.几乎形同之上..只是在光栅化处理前的操作不一样.即经过像素解码 像素传输.栅格化 最后形成片元...片元之后的处理完全一样..
可编程管线可以替换的功能
在着色器编程领域..你将可实现
- Vertex Shader(顶点着色器) 替换 顶点处理阶段
- Fragment Shader(片元着色器,又叫像素着色器) 替换 片元处理阶段
- Geometry Shader(几何着色器) 替换 图元组装阶段.
因为这三个阶段所决定都是最重要效果的阶段..对于这些的可编程将带来非常大的好处以及可控制的渲染!!
GPU
转自:GPU图形流水线
自从2006年以后,越来越多的研究人员把目光投向用GPU进行通用计算的GPGPU领域,在他们的努力下,很多原本由CPU执行的算法都有了GPU版本,它们的运行速度皆大幅提高[2]。随着GPGPU开发人员的增加,这种最初是"非主流"的技术变得越来越成熟,并影响了图形处理器的发展方向。终于,专门用于实现GPGPU技术的编程语言应运而生,它们被称为GPGPU语言,或GPU计算语言(GPU Computing Language)。最主要的语言有CUDA(Compute Unified Device Architecture,不过几乎没有人会记得这个全称)、OpenCL(Open Computing Language)、DirectCompute(DirectX的GPGPU解决方案)、Stream SDK(以前叫Close to Metal)和BrookGPU(即之前的Brook+)。前三个是目前市场占有率最高的。这些语言的设计目的就是封装GPU尽可能多的与CPU不同的特殊性质,提供对GPU进行通用计算编程的接口。它们被设计成具有近似于高级语言的语法特性,易于学习。另外,人们不用为了使用GPGPU而去学习过多的计算机图形学知识,相比用经典的GPGPU方法,它们在开始时的学习曲线比较平缓。
随着GPGPU语言的出现和GPU硬件的迅速升级,经典的GPGPU方法已经渐渐退出了人们的视线。在选择使用经典GPGPU方法或是GPGPU语言时,可以根据硬件环境优先考虑使用GPGPU语言。即只要有支持CUDA或OpenCL等的图形处理器,用户就不应考虑使用经典的GPGPU方法。
1.3.2 统一着色器模型
正如1.2.3节所述,GPU内部至少存在两种处理器:顶点着色器和片段着色器。虽然它们都是可编程硬件,但是它们的任务从根本上是不同的。例如,顶点着色器不能设定片段和像素的颜色,片段着色器也无法处理顶点的坐标变换。所以,在设计GPU硬件时,必须结合通常情况下图形处理任务的分配,令顶点着色器的数目和片段着色器的数目有个合理的比例,从而使计算资源达到最高的利用率。一般来说,片段处理器总是顶点处理器的2到3倍。
这样的分配终究是基于统计规律和架构设计的需要,却不可能做到所有处理器在所有时刻都处于忙碌状态。统一着色器模型(unified shader model)就是为了解决这一问题而出现的。依照这一模型设计的GPU内的所有处理器不再分为两类,而成了通用的计算单元。它们既可以处理顶点变换,又可以处理像素信息,不同任务由控制器实时地动态分配。NVIDIA GeForce 8000系列GPU是首批支持统一着色器模型的图形硬件。如图1-7所示为传统架构的GPU和支持统一着色器模型的GPU的结构示意图。
图1-7a所示为NVIDIA GeForce 6800架构。最上方的处理器阵列是顶点着色器,中间数量更多的是片段着色器。这属于传统的可编程GPU模型,顶点着色单元和片段处理单元是分立的。图1-7b所示为NVIDIA GeForce 8800架构。每个小方块代表一个标量处理器(scalar processor),或称线程处理器(thread processor),它们既可处理顶点,又可处理片段。每八个处理器组成一个多处理器(multiprocessor)。每两个多处理器被编在一个多处理器单元。这就是NVIDIA支持统一着色器模型的第一代GPU。
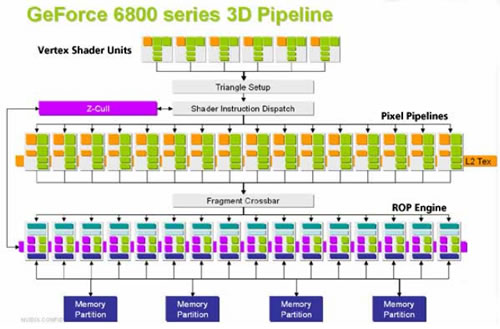 |
| 图1-7 两个GPU架构的例子:传统架构和统一着色器模型架构 a) 采用传统架构的NVIDIA GeForce 6800 |
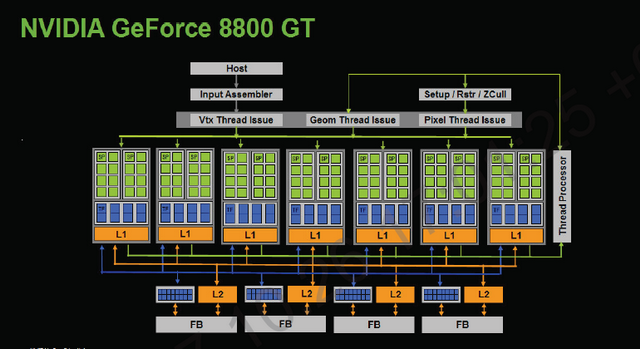 |
| (点击查看大图)图1-7 两个GPU架构的例子:传统架构和统一着色器模型架构(续) b) 采用统一着色器模型架构的NVIDIA GeForce 8800 |
传统的可编程GPU架构有分立的顶点着色器和片段着色器,这与图1-7a可以对应起来。但图1-7b的架构对读者来说可能有些陌生。它的外形同图形流水线的描述有些出入,但它的功能和传统GPU是完全相同的。在处理图形任务时,所有的处理器都可投入计算,不会因为功能的差异而浪费计算资源。事实上,对于GPGPU的开发人员来说,统一着色器架构比传统架构要简单得多,它提供给用户的是一个通用处理器阵列,支持高效的大规模并行处理计算。用户可对阵列中的每个处理器都一视同仁,不必考虑其中功能上的差异,此时,开发人员也不用花太多时间来研究硬件构造和计算模型,他们可以把更多的精力放在算法开发上。因此,支持统一着色器模型的GPU更适合GPGPU。
CUDA模型的大致计算流程可以归结为4步,如图1-8所示。
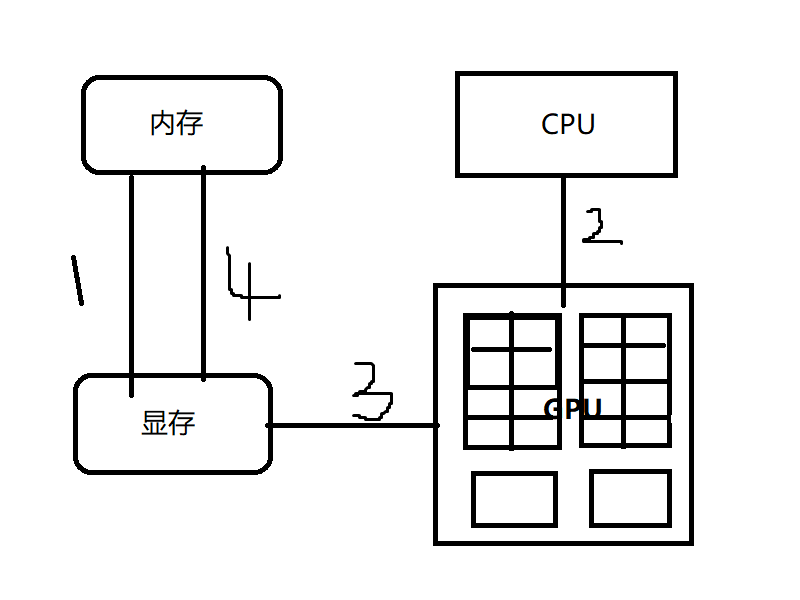 |
| 图1-8 CUDA模型的计算流程 |
1)把需要处理的数据从内存复制到显存中。
2)CPU把程序指令发送给GPU。
3)GPU的多处理器对显存中的数据执行相关指令,计算的过程中GPU可能需要频繁和显存交换数据。最后的计算结果存放在显存中。
4)从显存中把计算结果复制到内存里。
